Deep Dive into Distributed Transactions in TiKV and TiDB
The Percolator Transaction Model and Its Implementation in TiKV and TiDB
As the storage layer of TiDB, TiKV supports KV get/put/scan operations with single-digit millisecond latency. Furthermore, TiKV supports ACID distributed transactions across multiple TiKV nodes. TiKV&TiDB adopted the “Percolator” distributed transaction model to achieve this.
In the paper of “Large-Scale Incremental Processing Using Distributed Transactions and Notifications” , google introduced the Percolator model. Percolator provides cross-row, cross-table transactions with ACID snapshot-isolation semantics. Percolator is a typical 2PC model, including Prewrite phase and Commit phase. As showed in the following diagram, Percolator writes “data column(contain the real data)” and “lock column(lock info)” at the Prewrite phase, write the “write column”(commit info) and delete lock column at the commit phase. Data in all columns is persistent, including the lock column. So transactions can tolerate crash and other failures.
The following diagram shows a transaction that set A=1, B=2, C=3, with start-ts=100 and commit-ts=150. (It doesn’t matter if you don’t understand the diagram now, I will explain it more later).

Monotonic timestamps: start-ts and commit-ts
The numbers like 100, 150 in the above diagram are monotonic timestamps. In this example, 100 is the the start timestamp of this transaction, and 150 is the commit timestamp of this transaction. All these timestamps in TiKV&TiDB are allocated from PD (placement driver).
Each key can have multiple versions (MVCC) in Percolator model, TiKV encodes the start-ts to the end of all the keys in the “data column” and encodes the commit-ts to the end of all the keys in the “write column” to achieve this. TiKV doesn’t encode timestamp to the keys in the “lock column”, because there is only one transaction that can modify (occupy) a key at the same time. In TiKV, a transaction needs to acquire an in-memory exclusive lock (acquire latches)before this transaction can modify the disk based lock column, so we can ensure there is just one transaction doing the modification operation at the same time.
Primary key is the first key to commit or rollback
In the Percolator transaction model, each transaction will pick a key as the primary key, and the primary key will be used as the transaction state(committed, rollbacked, or not determined yet) indicator. The primary key is the first key committed or rollbacked during the 2nd phase. If the primary key is committed, it means the transaction is committed, if the the primary key is rollbacked, it means the transaction is rollbacked. TiKV uses the first key (in binary byte ordinary order) as the primary key by default. There is a potential optimization that chooses the shortest key as the primary key to reduce total write bytes, because all other key locks need to copy the primary key.
Crash recovery
The transaction (client) may encounter a crash before committed the primary key or after committed the primary key.
If the transaction encounters a crash after committed the primary key but before committed other secondary keys, the transaction state is committed. When other read transactions read these uncommitted secondary keys, they will check the state of the primary key and help to commit these secondary keys. Because the lock of secondary keys contains the primary key.
If a transaction encounters a crash before committed the primary key, the transaction state is uncommitted. Other read transactions that read these uncommitted keys of this uncommitted transaction, they will help to rollback this uncommitted transaction, to make sure following read or write transactions will not be blocked. Rollback a uncommitted transaction is safe because the client hasn’t send OK response to the application yet before its crash.
MVCC
In TiKV, each modification (Put/Update/Delete) for a specified key will add a new version. For example the following diagram shows, there are 3 versions for the key A. The key A experienced transactions SET A = 1, DELETE A, SET A = 10. Each read transaction needs to acquire a latest timestamp from PD when this transaction started, to read the latest version of data it can see. The read transaction find the largest commit information less than or equal to its timestamp in Write column first, and then use the start-ts to locate the real value in the Data column. In the same example, a read transaction with timestamp 309 can read the Delete version of the key A, it means this transaction read empty from key A or key A is not existing to this transaction; a read transaction with timestamp 310 can read the latest version of data (value is 10) for key A.

As more and more transactions go on, there will be many versions for some keys. These pileup MVCC versions may slowdown range scan requests, occupy more disk space, decrease block-cache efficiency, etc. So we need a mechanism to clean these unused old versions data correctly and efficiently, and this is where the GC mechanism comes from.
The safe-point and GC
In order to ensure the correctness of all read and write transactions, and make sure the GC mechanism works, TiKV/TiDB introduced the concept of safe-point. There is a guarantee that all active transactions and future transactions’ timestamp is greater than or equal to the safe-point. It means old versions whose commit-ts is less than the safe-point can be safely deleted by GC.
The default value of safe-point is current timestamp minus gc-life-time(10 minutes by default). And there are two main components that participate the GC procedure, GC coordinator and GC workers.
GC coordinator’s main purpose is advance the safe-point of the whole cluster: (in tikv-client, if you run TiKV as an independent cluster, you should start the GC coordinator by yourself, and if you run TiKV with TiDB, the GC coordinator is embedded in the TiDB server)
1) Calculate the new safe-point (current timestamp minus gc-life-time), clean up uncommitted transactions whose timestamp are less than the new safe-point;
2) Publish the new safe-point to the configuration center PD;
3) Repeat 1 and 2 periodically.
GC workers (in TiKV server):
Each TiKV has a GC-worker, it fetches the new safe-point periodically from configuration center and does GC work. There are two different choices to do the GC work: regular GC and GC with compaction-filter. It is configured by TiKV configuration “gc.enable-compaction-filter = false|true”.
For the regular GC, TiKV’s GC workers will do GC work range by range. The GC worker checks the MVCC statistics (this is stored in SST files’ user properties block, and collected during SST files’ generating) of this data range, and if the MVCC statistics indicate that there are many MVCC versions in this data range, the GC worker scans this data range key by key and deletes these old versions. For each key, at least 1 visible version less than or equal to the safe-point must be kept. For example, the safe point is 10, and the key A has 5 versions with commit-ts are 20 Put, 15 Put, 9 Put, 8 Put, 7 Put. Versions with commit ts 7 and 8 can be deleted safely, but version with commit-ts 9 cann’t be deleted because there might be transactions with timestamp 10 or 11 to read this version. There is an exception if the operation of commit-ts 9 is Delete, it can be deleted by GC because read a version with Delete operation equals to this version is not exist.
The regular GC works well in nearly every case, and it works as expected, but with one drawback that it consumes some resources(IO and CPU) to scan delete data. And then, TiKV leveraged RocksDB’s compaction filter to reduce the resources consumption of GC. TiKV drops old versions by compaction filter during the background compactions are ongoing. But GC with compaction filter is not perfect, it depends on compaction to trigger the GC works, in most cases the compaction will be triggered if there are some writes (insert/update/delete) which is the root cause of generating new MVCC versions, but in some corner cases the compaction is not triggered in time even there are some writes.
In-Memory Consistent Cache (IMCC)
In order to overcome the potential slow scan issue when there are many MVCC versions for some data ranges due to GC is not triggered in time or the default GC safe-point (10minutes) is not aggressive enough, TiKV is introducing the In-Memory Consistent Cache. The basic idea of IMCC is to use a memory data structure to cache the most recent MVCC versions of these frequently updated ranges, and we use a more aggressive GC safe-point like 30s or 1 minute for this in-memory consistent cache. For most of read requests, their timestamps are fresh enough to be served by this aggressive GC safe-point and will not suffer from the issue caused by too many MVCC versions, if a read request has a timestamp less than the aggressive GC safe-point, it will fallback to read data in the RocksDB.
TiKV uses RocksDB’s WriteCallback interface to make sure the write between RocksDB and the IMCC is atomic, and the read view between RocksDB and IMCC is consistent.
Long-running transactions in TiDB
If we advance the safe-point rudely, these long-running transactions like bulk load, long-running JOIN queries will be interrupted unexpectedly. Instead of advancing the safe-point blindly by the gc-life-time, each TiDB instance keeps tracked all active transactions, and publishes the active transaction with smallest timestamp to the configuration center PD. And the GC coordinator uses the smallest active timestamp of the whole cluster as the safe-point min. In this way, these long-running transactions can complete as expected.
Alignment between TiKV storage engine and the Percolator transaction model
TiKV uses RocksDB as the internal storage engine. RocksDB is a widely used high performance kv storage engine with plenty of features like multiple thread compaction, column families, sub-compaction in L0, ingesting SST files, etc.
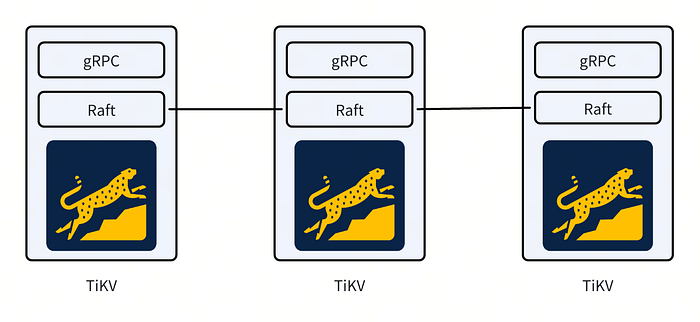
RocksDB Column Family
RocksDB has supported column family(CF) since v3.0. Different column families share the same WAL and sequence number mechanism, but each column family has its own memtable and sst files. In this way, with RocksDB CF we can achieve goals like:
1) Atomic writes across different column families. The atomicity is guaranteed by the shared WAL (and the same sequence number mechanism).
2) Physically isolate data in different column families. Data in different CF stored in different memtable and SST files.
3) Configure different CF independently according to their reads/writes mode to achieve better performance.
Besides the above goals, we also can get a consistent view of the database across Column Families. This is helpful when we use RocksDB as a cornerstone to build a database that supports ACID transactions.
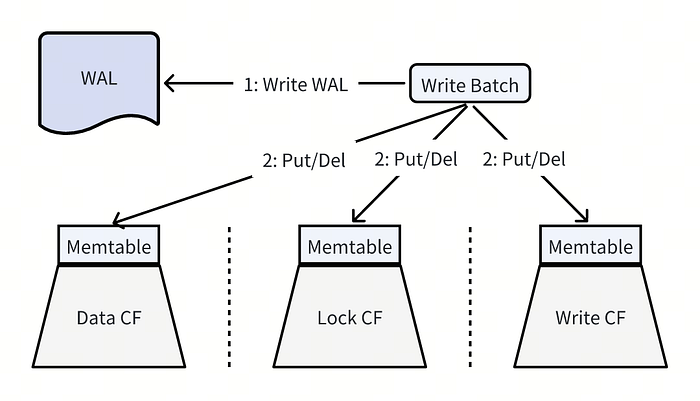
Align Percolator Model with RocksDB Column Families
V1: use different prefix to implement percolator data model
At the beginning, TiKV implemented the percolator transaction model without using the column family feature of RocksDB. There was just one column family (the default cf), TiKV added different prefix (D(data), L(lock), W(write)) to represent percolator model. The data layout looks like this:
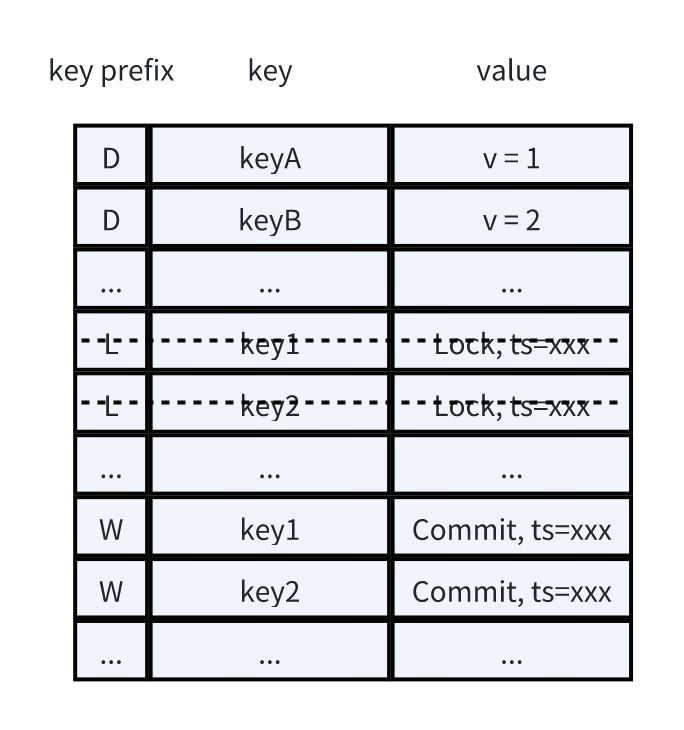
From above percolator transaction mode introduction we can see that the lock data just exist when the transaction is ongoing, lock will be deleted as soon as the transaction is committed or rollbacked. So there would be many RocksDB deletion tombstones for the range of lock data. These tombstones may slow down the performance of following lock reading operations. And then we want the lock data range has more aggressive compaction policy to drop these deletion tombstones. Unfortunately, we can’t configure aggressive compaction just for the lock data range because all the data share the same configuration.
V2: align RocksDB column family with percolator data model
And then TiKV adopted RocksDB column family feature around 2016. TiKV used a dedicated column family to store data, lock and write information respectively. The data has been organized as:
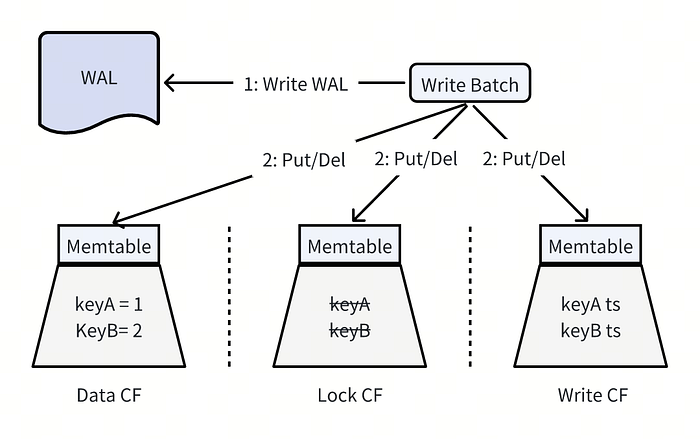
For different column families, TiKV used different configurations according to the read/write mode of the data. For example, lock CF is configured aggressive compaction policy like set level0-file-num-compaction-trigger=1 to trigger SST files in L0 compact with L1 aggressively to accelerate the read performance, periodic full compaction to clean deletion tombstones in time, etc. For the Data CF and Write CF, zstd compression is set for the most bottom 2 levels to store more data.
Optimizations TiKV and TiDB have Made
Embed Short Value into Write CF
In the Percolator Transaction Model, each read request involves at least 2 CF, read the Write CF first and then read the Data CF. For example a read transaction with timestamp 320 will read the red colored content as the following diagram shows.

TiKV made an optimization that embeds the short value into Write CF. If the content size is less than 255, the content will be embedded in the Lock during the Prewrite stage, and move the content to Write CF during Commit stage. After this optimization, we eliminate the write in Data CF for these keys with short content, and eliminate the read in Data CF.
After Prewrite:

After Commit:

After this optimization, point select read-only workload achieved more than 10% improvement.
1PC
If a transaction only involves KV pairs located in a single node (one TiKV data range in our case), 1PC is adopted to accelerate the transaction and reduce transactions resource consumption. After introducing this optimization, when running sysbench oltp_update_non_index workload over TiDB, the throughput increased by 87%, and the average latency reduced nearly 50%.
There was a technical challenge when we introduced 1PC optimization in TiKV and TiDB, the challenge was how to calculate the commit ts for 1PC transactions correctly. In 2PC transactions, we fetch the commit-ts from PD(monotonic TS service) after all keys have been prewritten successfully. But in 1PC transactions, we can’t follow the same logic because 1PC just involves 1RPC to complete the transaction. Let me explain more by an concrete example. In the following digram, there are two transactions A and B, the transaction A is a read transaction read data twice with the same timestamp 300, and the transaction B is a write transaction set the content by 1PC. In step 3, transaction A can’t see the content and don’t encounter any lock, but in step 5 transaction A sees the content set by transaction B in step 4.

If transaction B is a 2PC transaction, step 3 in transaction A will encounter the lock and wait for the transaction B complete. So the 2 reads in transaction A have a consistent result.

TiKV introduced a cache to record the max timestamp this TiKV has experienced, and this max-ts will be used when calculate the commit-ts of 1PC transactions in this TiKV, the commit-ts calculation formula is max(start-ts+1, max-ts+1). For the above example, the commit-ts of transaction B will be 300+1.

Async Commit
1PC is fantastic, it has a great improvement both for latency and overall throughput. But 1PC has a strong constraint that all modifications are located in the one TiKV. To reduce the latency for broader write transactions, TiDB introduced the async commit feature in V5.0. For the sysbench oltp_update_index workload, the average latency is reduced by 42% and the 99th percentile latency is reduced by 32% by introducing async commit feature.
The basic idea of async commit is that the transaction state is determined when all keys have prewritten successfully, so the transaction can return success state to client earlier. Async commit only take effect when the transaction involves not too many keys because the primary key will store all keys to keep track of them to keep consistency in case of crash recovery. More detail please refer to this blog.
